|
Adversarial scratches: Deployable attacks to CNN classifiers
Abstract
A growing body of work has shown that deep neural networks are susceptible to adversarial examples. These take the form of small perturbations applied to the model's input which lead to incorrect predictions. Unfortunately, most literature focuses on visually imperceivable perturbations to be applied to digital images that often are, by design, impossible to be deployed to physical targets.
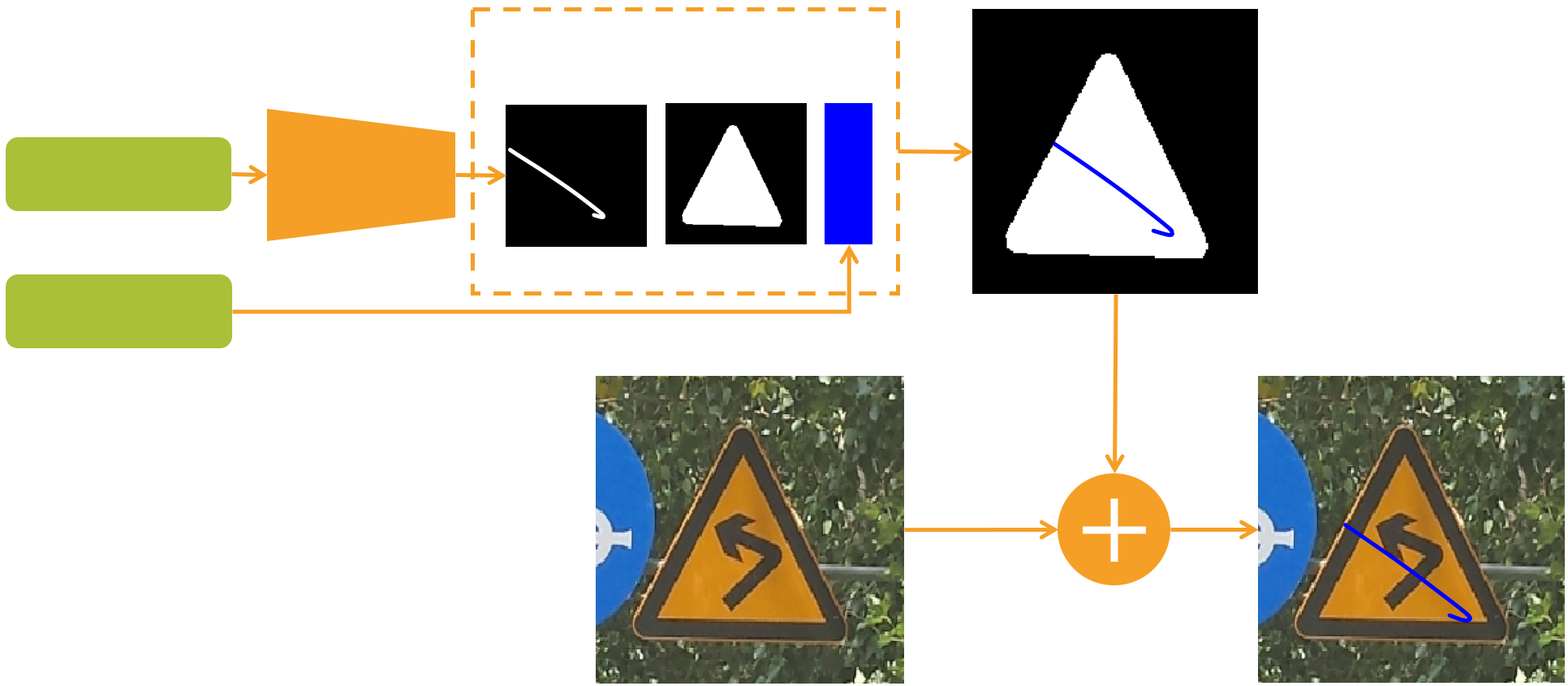
Fig.1: Attack application methodology. From the parametric description of the attack, a perturbation can be constructed, masked, and then applied to the image, thus obtaining the adversarial image. Adversarial Scratches Adversarial Scratches are a particular type of adversarial attacks that achieve state-of-the-art performance while perturbing a surprisingly small number of pixels and requiring very few iterations. The main principle allowing such performance is a compact parametric formulation of the attack model, which enables efficient search of a successful perturbation. Adversarial scratches can be applied to a physical target, in such a way that they resemble graffiti or damage. For this reason, we say that Adversarial Scratches are deployable. Attack Model Adversarial Scratches are modelled as Bézierzier curves, which can describe a wide range of shapes with very few parameters. Indeed, a second-order Bézierzier can be defined by just 9 parameters, where six of these define the coordinates of the control points, and three define the color of the scratch. A successful perturbation can be obtained by attacking the target model while iteratively optimizing the parameters of the scratch. In our work, we use Neuro-Genetic Optimization. Results We perform an extensive analysis of the performance of Adversarial Scratches in a variety of scenarios, and explore different parametric configurations. Our methods show better performance than other deployable state-of-the-art attacks, in terms of Fooling Rate, Average Queries, and Median Queries, while perturbing fewer pixels. Moreover, in a realistic scenario where the perturbations are applied to images of traffic signs, Adversarial Scratches have achieved 100% Fooling Rate. Our attack has also been shown to be effective against the publicly available Microsoft Cognitive Services API. Our code is available for download here
|
|
References [Giulivi et al. 2022] Adversarial scratches: Deployable attacks to CNN classifiers |